La RATP peut encore travailler sur ses données Open Data
Comme beaucoup, je me suis réjouis de voir que la RATP rejoignait enfin le mouvement Open Data. Mais j’ai vite déchanté en voyant la faible qualité de celles-ci…;
L’échec de la RATP pour libérer des données
{kind=link}
D’abord, parlons de ce qu’il y a:
- la liste des « positions géographiques des stations »
- la liste des « correspondances ». Il s’agit en fait de la liste de (id_station, ligne).
- les plans « emblématiques » et pictogrammes
Les défauts
Cela semble bien parti sauf qu’il y a multitude de défauts.
La liste des stations est un référentiel simple, voire simplet
-
La fiche sur data.gouv.fr a une documentation sommaire:
ID ; X ; Y ; nom station ; Ville/CP ; réseau. Les données de géolocalisation sont au format WGS84 (format GPS).
Contrairement à son nom « ville/cp » ne contient que la ville (sauf pour Paris où il y a aussi l’arrondissement). Concernant la signification de X et Y, il s’agit en fait des longitude et latitude (et dans la notation WGS84, on écrit dans l’autre sens: d’abord latitude puis longitude) </li>
- la position est le barycentre des entrées. Or, moi je prends les escaliers, je ne creuse pas de tunnel…; Il aurait été plus intelligent de fournir la liste des entrées (et encore mieux: sont-elles accessibles aux handicapés?)
- La plupart des stations ont une casse correcte, mais certaines stations sont incorrectement entièrement en majuscules (pour le tramway)</ul>
Le fichier « correspondances » est improprement nommé, puisqu’on y trouve tous les quais, y compris ceux qui ne constitue pas une correspondance.
- Il pourrait être plus simple à parser si le nom court de la ligne (ex « A » pour le RER A) était isolé des débuts et fins de ligne (actuellement » A (Marne-la-Vallée-Chessy – Boissy-St-Leger/Cergy-St-Christophe – Poissy – St-Germain-en-Laye) « )
- Les noms de ligne ne sont pas très cohérants, puisque un numéro parfois (ex D ((81) Melun/(81) Orry la ville Coye). J’ai réalisé que cette ligne D était en fait plus précise, car cela permet de distinguer les différentes branches. Par contre, ça semble du chinois, il faudrait que quelqu’un passe plus de 10 secondes à modéliser les données, non?
- surtout, une information cruciale est manquante: le numéro de séquence de l’arrêt dans la ligne. Aujourd’hui, il n’est pas possible de déterminer l’ordre dans lequel les stations se suivent quand le train circule!
Même les pictogrammes sont faux. En effet, les images fournies en Open Data sont entièrement transparentes.

Cela pose un réel problème de visibilité. Or, le plan schématique montre bien que ce n’est pas ainsi que le pictogramme doit être représenté. L’intérieur du cercle devrait être un disque blanc
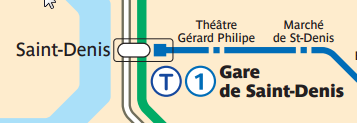
Des informations qui auraient apporté de la valeur…;
Mais je ne veux passer casser ce bon élan, car j’aimerais aussi
- où se trouve la correspondance par rapport au train (première voiture, deuxième voiture, etc); cela m’aiderait à finir Zazie
- les données pour les bus
- les horaires
- un peu d’union avec la SNCF pour fournir toutes les données…;
Inexploitable aujourd’hui
Certes, c’est le geste qui compte, et c’est embryonnaire. Mais pour le moment, les données « libérées » sont déjà connues de tout le monde. Et puis, elles sont à peu près inexploitables. D’ici à penser que c’est volontaire…;